什么是机器学习
首先我们思考一个问题,机器学习是什么?对于这个问题,不同的人有不同的理解。
在没有明确设置的情况下,使计算机具有学习能力 ——Samuel
计算机程序从经验 E 中学习,解决某一任务 T,进行某一性能度量 P,通过 P 测定在 T 上的表现因经验 E 而提高 ——Tom Mitchell
就普遍意义上来说,机器学习就是通过经验自动改进程序的一个领域。 通常的分类有四种:
- 1、监督学习(Supervised learning)
- 2、无监督学习(Unsupervised learning)
- 3、强化学习(Reinforcement learning)
- 4、推荐系统(Recommender systems)
监督学习(Supervised learning)
通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的。也就具有了对未知数据分类的能力。监督学习的目标往往是让计算机去学习我们已经创建好的分类系统。
也就是说,计算机处理的是已经经过标记的样本,经过训练之后,我们给它一个未经标记的样本,计算机给出相应的标记或结论。
下面是一些重要的监督学习算法:
- K 近邻算法
- 线性回归
- 逻辑回归
- 支持向量机(SVM)
- 决策树和随机森林
- 神经网络
常见的监督学习算法分类:回归分析(Regression)和统计分类(Classification)。
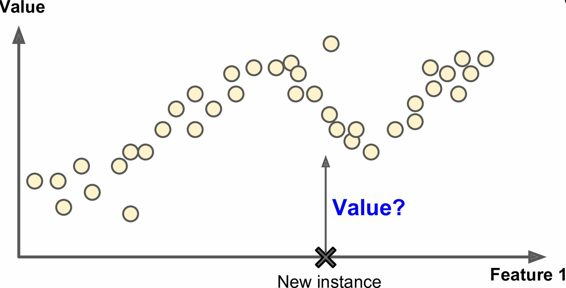
回归(Regression)
回归的特征就是来对于给定标签的数据,通过大量的训练,来得出一个可以预测目标数值的系统。例如给出一些特征(里程数、车龄、品牌等等),来预测一辆汽车的价格。
分类(Classification)
垃圾邮件过滤器的分类的就是一个经典的分类问题,用许多已经分类(垃圾邮件或普通邮件)的邮件样本进行训练,过滤器能对新邮件进行分类。
无监督学习(Unsupervised learning)
无监督学习的目标则是没有标签的数据,需要计算机自己去学习怎么做。
下面是一些重要的无监督学习算法:
- 聚类
K 均值
层次聚类分析(Hierarchical Cluster Analysis,HCA)
期望最大值 - 可视化和降维
主成分分析(Principal Component Analysis,PCA)
核主成分分析
局部线性嵌入(Locally-Linear Embedding,LLE)
t-分布邻域嵌入算法(t-distributed Stochastic Neighbor Embedding,t-SNE) - 关联性规则学习
Apriori 算法
Eclat 算法
半监督学习
一些算法可以处理部分带标签的训练数据,通常是大量不带标签数据加上小部分带标签数据。这称作半监督学习。
强化学习
类似于反馈,一个典型的强化学习的例子就是 AlphaGo,它是通过分析数百万盘棋局学习制胜策略,然后自己和自己下棋。